はじめてのCNN【Digit Recognizer】
はじめに
僕自身deepの知識が乏しかったので,「ゼロから作るDeep Learning」を読みました.初心者でも非常に分かりやすく解説されており,理解が深まって良かったです.今回はkaggleでdeepの実装をしていきましょう!
内容としてはCNNで文字識別を行います.
↓CNNを初心者向けに解説しているKernelsがあったのでそちらを参考にさせて頂きました.
https://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6
↓ゼロから作るDeep Learning
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
↓deepについて分かりやすくまとめてあるサイトがあったのでこちらも紹介します
http://gagbot.net/machine-learning/ml4
Kerasのインストール
まずはshellでkerasのインストールpip install keras
もろもろインストール&データセットのダウンロード
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mpimg import seaborn as sns %matplotlib inline np.random.seed(2) from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix import itertools from keras.utils.np_utils import to_categorical # convert to one-hot-encoding from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D from keras.optimizers import RMSprop from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ReduceLROnPlateau sns.set(style='white', context='notebook', palette='deep') # Load the data train = pd.read_csv("input/train.csv") test = pd.read_csv("input/test.csv")
データの確認
可視化
Y_train = train["label"] # Drop 'label' column X_train = train.drop(labels = ["label"],axis = 1) # free some space del train g = sns.countplot(Y_train) Y_train.value_counts()

非常にバランスよくデータが集まってますね.
欠損値の確認
X_train.isnull().any().describe()

test.isnull().any().describe()
欠損値もありませんね.とてもキレイなデータであることが分かります.
事前処理
事前処理として以下を行います- 各要素の正規化
- 1次元のベクトルを2次元に変換
- ラベルをone hot ベクトルにする
# 0~255を0~1に正規化 X_train = X_train / 255.0 test = test / 255.0 # 1×784→28×28に変換(1次元→2次元に変換) X_train = X_train.values.reshape(-1,28,28,1) test = test.values.reshape(-1,28,28,1) #ラベルをone hot vectorsに (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) Y_train = to_categorical(Y_train, num_classes = 10) random_seed = 2 # 訓練データを分割 X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1, random_state=random_seed)
どんな感じの画像か確認してみる
g = plt.imshow(X_train[2][:,:,0])

9ですね.
モデルの作成
In -> [[Conv2D->relu]*2 -> MaxPool2D -> Dropout]*2 -> Flatten -> Dense -> Dropout -> Out となるCNNを作成します.入力→畳み込み(Conv2D)→活性化(relu)→プーリング(MaxPool2D)→正則化(Dropout)→一次元に直す(Flatten)→全結合(Dense)→出力
という流れになっています.
softmax関数により,出力のベクトルの要素にはそれぞれの確率が格納されています.
# CNN model model = Sequential() model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu', input_shape = (28,28,1))) model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same', activation ='relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu')) model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu')) model.add(MaxPool2D(pool_size=(2,2), strides=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(256, activation = "relu")) model.add(Dropout(0.5)) model.add(Dense(10, activation = "softmax"))
最適化・損失関数の設定
モデルが作成できたら,最適化の方法と損失関数を定義します.最適化にはRMSpropを,損失関数にはcategorical_crossentropyを使用します.また,エポックとバッチサイズの設定も行います.
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0) model.compile(optimizer = optimizer , loss = "categorical_crossentropy", metrics=["accuracy"]) epochs = 1 # Turn epochs to 30 to get 0.9967 accuracy batch_size = 86
過学習を抑えるために
データ数がたくさんあれば過学習を抑える事ができます.ということで,過学習を抑えるために訓練データの拡張を行います.どのように拡張するかと言うと,例えば,人が文字を書くとき,は文字の大きさがバラバラだったり,文字がずれてたりしますよね.それと同じように,訓練データを数字の位置を変える・大小を変える・回転させるなどの処理を行ってデータ数を増やします.そのような処理を行うことで簡単にデータを増やす事ができます.以下を行ってデータを増やします.※6と9の判定を間違えてしまうため,反転は行いません.
- 少し回転させる
- 少し大きくする
- 少し位置を動かす
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
学習
訓練データを学習してみます.# Fit the model history = model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size), epochs = epochs, validation_data = (X_val,Y_val), verbose = 2, steps_per_epoch=X_train.shape[0] // batch_size , callbacks=[learning_rate_reduction])
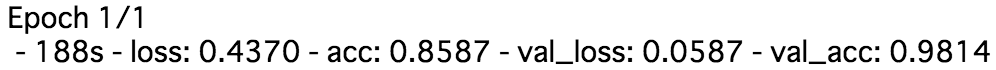
精度98%ととても高い結果が得られました.
性能評価
テストデータを予測します.# predict results results = model.predict(test) # select the indix with the maximum probability results = np.argmax(results,axis = 1) results = pd.Series(results,name="Label") submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1) submission.to_csv("cnn_mnist_datagen.csv",index=False)
テストデータの精度は0.98371%でした.
かなり高い精度の学習モデルができました.